In this article you will learn how to deploy Librechat on Kubernetes and how to configure cloud based LLM providers and custom providers.
Librechat configuration structure
Librechat is distributed as a container available on it’s github repo.
In order to run it, you have two options :
- docker compose : that’s the primary deployment target
- kubernetes using a helm chart : Maintained in the github repo.
Historicaly, Librechat was configured using a .env file where you can define a predifined list of env variables.
Due to the constant increase of new options, an additionnal yaml based configuration file as been added here
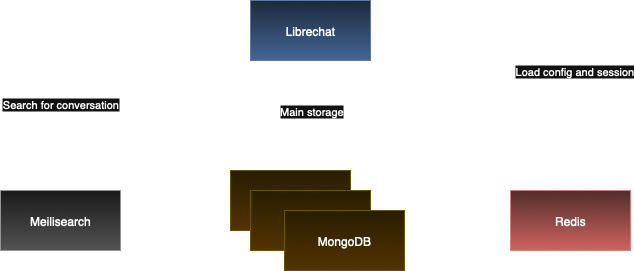
Architecture
Choose your LLM provider
Those two provider offers free plan without putting your credit card
OpenRouter
You can select the list of free models by selecting only the free models
The openrouter config should look like
|
|
Don’t forget to create an API KEY
Mistral AI
Mistral AI is a french AI company that offer also a very interesting free plan (something like 1 billion of tokens which is quite enough for a unique user or for testing purpose)
Have a look at Mistral API Console and create an account.
The mistral config should look like :
|
|
Use a local provider
This usecase will need an additional componenet in order to provide a unique entrypoint like portkey or LiteLLM. I personally use LiteLLM which is easier to configure.
Inference engine
Depending on your local GPU infrasctructure and the number of users there is plenty of inference engine you can use.
Ollama
For very small number of users, Ollama is a good catch for first try as it propose a long list of supported models. The drawback is that it is intended to be run on small gpu cards so the models are usually heavily quantized in order to fit on commodity hardware. They usually are quite slow to respond and are intended to be used for a very few users.
VLLM
VLLM is actually the most famous inference engine as it support nearly all models and provide a good batching for multiusers use case.
Authentication
As I am already using a keycloak instance with Cisco Duo (look at my old articles for that), I use the OpenID Connect implementation on Librechat.
Enhance Librechat with RAG, MCP Server….
And there is more functionnality, like RAG (upload pdf files to enhance models using your files), Image generation, Agents, MCP Servers….
Feel free to contact me if you need assistance :-)